AWS Cheat Sheet Well-Architected Framework
Aws Well-Architected Framework
This study guide will cover the best practice in the design, delivery and maintenance of AWS environments based on 5 pillars.
This cheat sheet is based on this whitepaper AWS Well-Architected Framework
I will encourage you to read each specific whitepaper for each pillar and make the LAB. You can find all this whitepaper there : [AWS Well-Architected Framework whitepaper]https://aws.amazon.com/architecture/well-architected/?ref=wellarchitected-wp&wa-lens-whitepapers.sort-by=item.additionalFields.sortDate&wa-lens-whitepapers.sort-order=desc
Basically, this post will cover the best practice to be a good architect on AWS, it’s a very important part of the certification and it’s very important in my opinion to know and use these best practices in a all day IT job.
AWS provide this great tool AWS Well-Architected Tool to review your architecture and provide you recommendations for making your infrastructure more reliable, secure, efficient and cost-effective.
General Design Principles for AWS cloud computing
- Stop guessing your capacity needs. You just pay for you need and you can scale up and down easily automatically.
- Test systems at production scale. you can make a test environment very fast and you only pay when it’s running.
- Automate to make architectural experimentation easier and faster.
- Allow for evolutionary Architecture - innovation as a standard practice.
- Drive architecture using data - Use data/logs collected to improve your workload
- Improve through game days - simulate events in production, test your disaster recovery plan
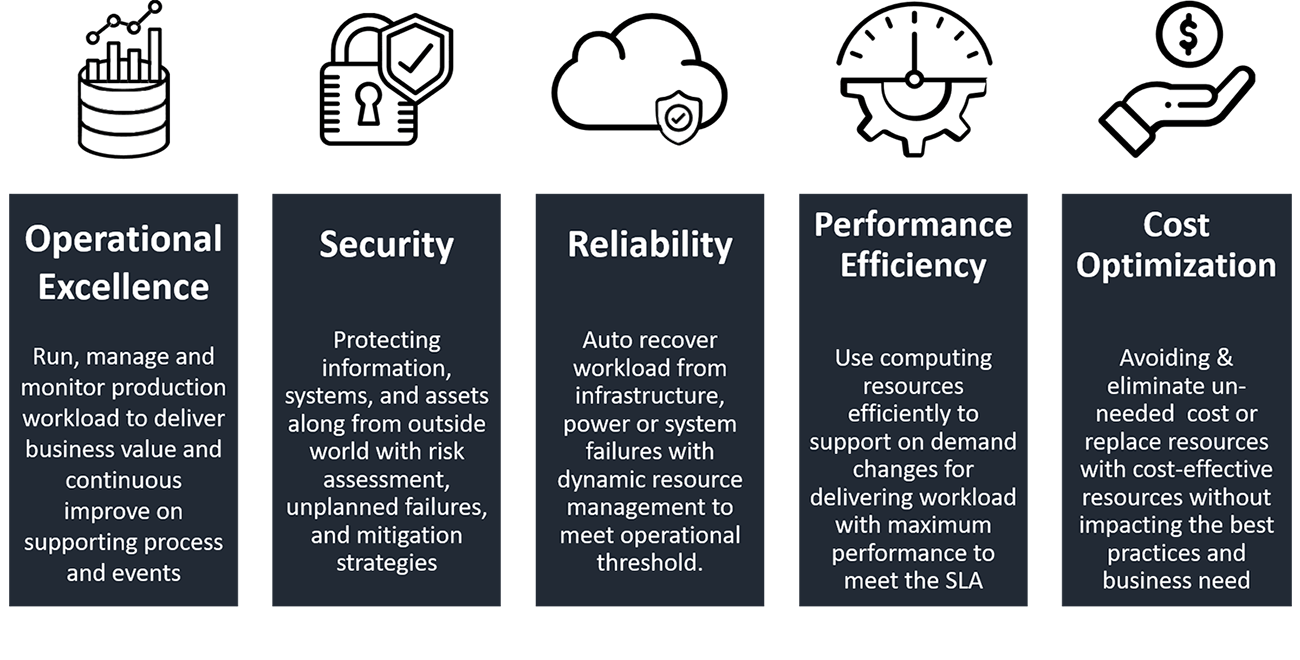
The Five Pillars of the AWS Well-Architected Framework
- operational excellence
- security
- reliability
- performance efficiency
- cost optimization
This should be the foundation of your architecture/infrastructure to build stable and efficient systems.
Operational excellence
![]()
The ability to support development and run workload effectively , gain insight into their operations, and to continuously improve processes and procedures to deliver business value.
Design principe for Operational Excellence
- Perform Operation as a code -> use IAC Tools like Terraform, cloudformation
- Make frequent, small, reversible changes -> Updates regularly
- Refines Operations procedures frequently -> Improve procedures continuously
- Anticipate failure, be proactive ! -> Test your failures scenarios and validate the impact, test your responses procedures, set up regular games days
- Learn from all operational failures. Learn and Improve from failures and share with your teams and organization
Best practice for Ops Excellence
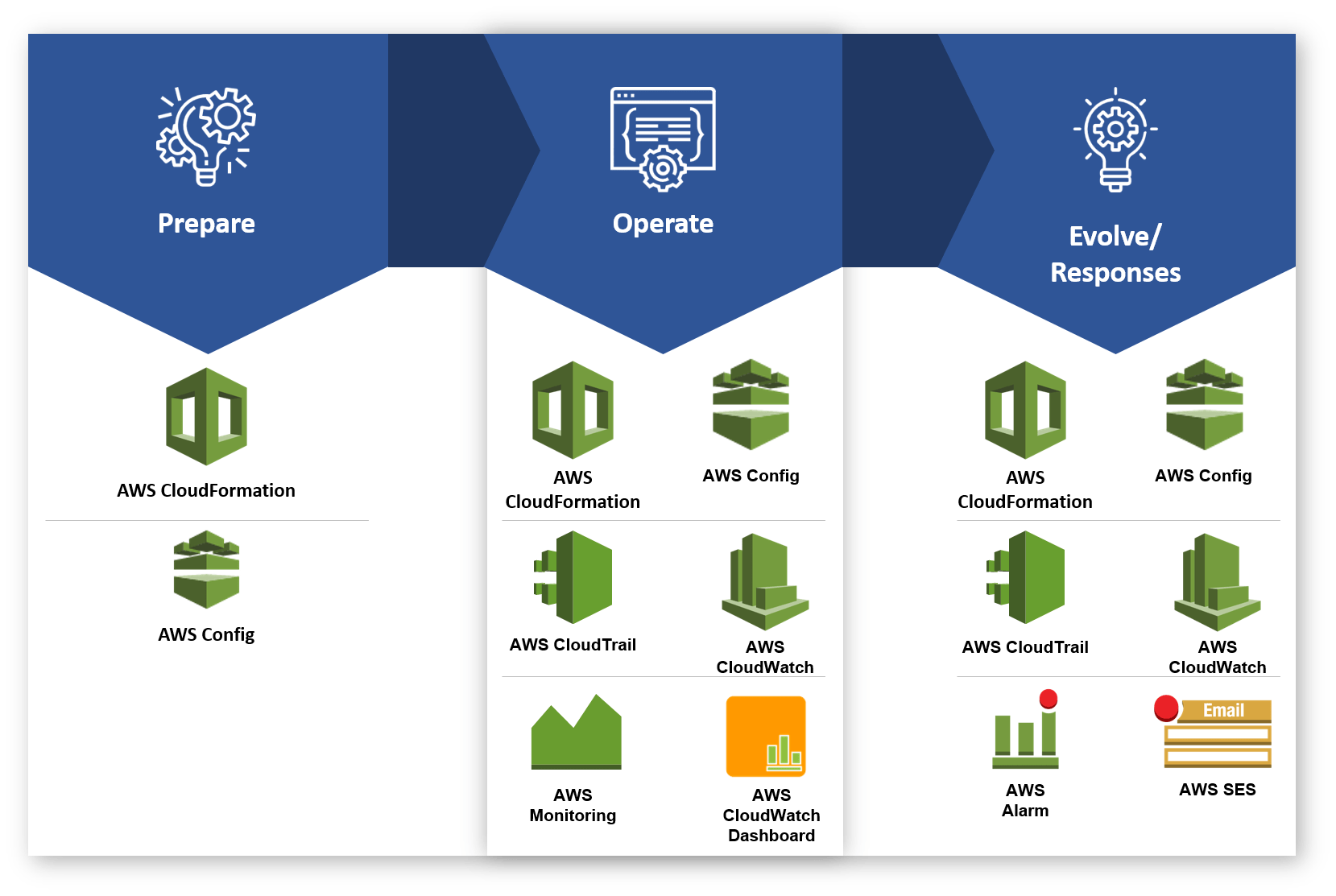
- Organisation
- How do you determine what your priorities are?
- How do you structure your organization to support your business outcomes?
- How does your organizational culture support your business outcomes?
- Prepare - Amazon CloudWatch, Aws Cloudtrail
- Understand your workload ( metrics, logs, events, traces) and they expected behaviors. Observe and monitor.
- How do you design your workload so that you can understand its state?
- How do you reduce defects, ease remediation, and improve flow into production?
- How do you mitigate deployment risks?
- How do you know that you are ready to support a workload?
- TAG correctly and organize your resource by AWS resource groups to identify them fast
- Operate
- Use KPI based on metrics,log to see where you can improve
- How do you understand the health of your workload?
- How do you understand the health of your operations?
- Evolve
- How do you evolve operations?
Security
![]()
The ability to protect data, systems and assets to take advantage of cloud technologies to improve your security.
Design principes for Pillar Security
- Implement a strong identity foundation -> principle of least privileges and centralize Identity Management (IAM)
- Enable Traceability -> Monitor, alert and audit actions and changes to your environment in real time (cloudwatch, cloudtrail, SNS)
- Apply security at all layers ! ( VPC, load-balancing, app, EC2, OS, code, …)
- Automate security best practice
- Protect data in transit and at rest
- Keep People away from data
- Prepare for security events - Incident Management and investigation policies
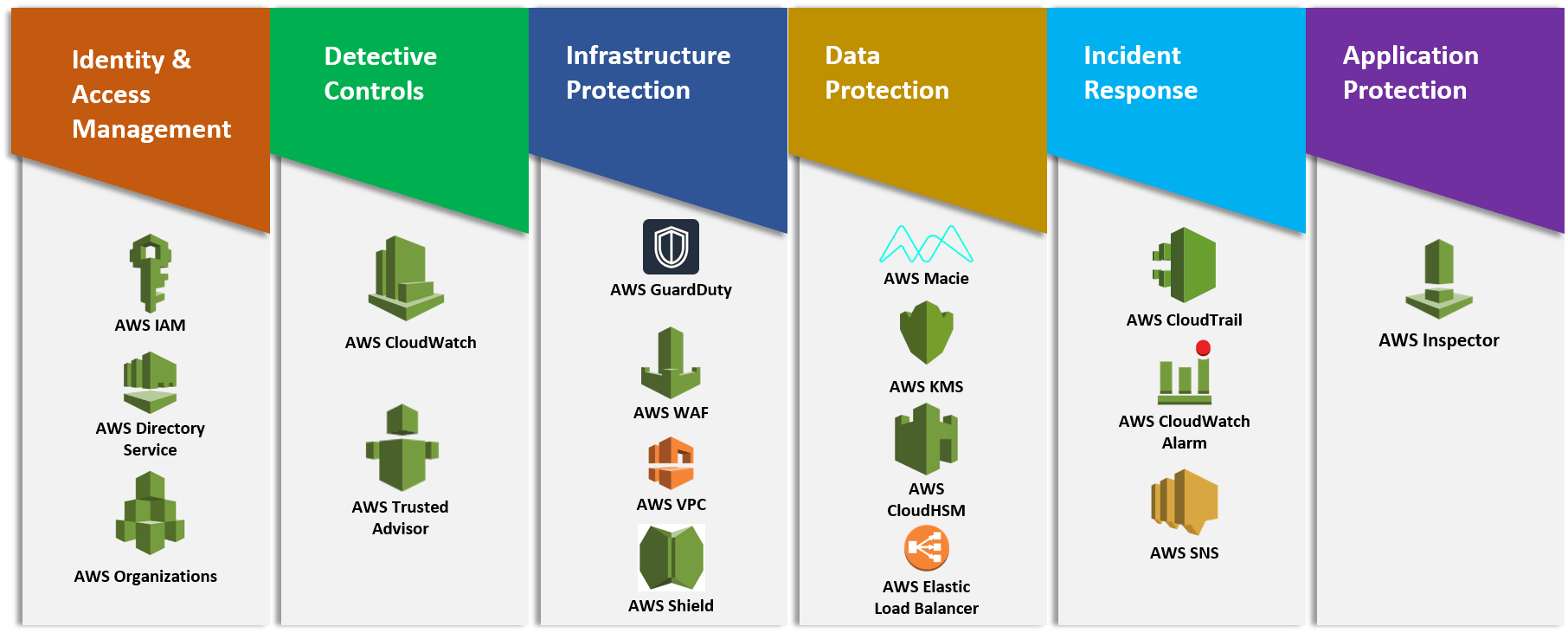
Best practice for Security Pillar
-
Security -> How do you securely operate your workload?
- Automate security processes, testing and validation in all layer level
- Segregate different workload by account, based on their function and compliance or data sensitivity requirements
-
Identity and Access Management IAM - How do you manage identities/permissions for people and machines?
- Privilege management with strong credential management, credentials must not be shared
- Apply granular policies which assign permission to a user, group, role or resource.
- Strong password practice, enforcing MFA and complexity level
-
Detection How do you detect and investigate security events?
- Use detective control to identify a potential security threat or incident, make internal auditing.
- on Aws, you can use CloudTrails logs, AWS API Calls and CloudWatch for monitoring and AWS Config will provide you configuration history.
- Importance of Log Management
-
Infrastructure Protection -> How do you protect your network and compute resources?
-
Data Protection -> How do you classify your data? How do you protect your data at rest and in transit?
- Organize your data based on level of sensitivity and encrypt them if sensitive
- Backup and Storage durability ( 99,9x11 ) Durability for all S3 Storage.
- Use versioning
-
Incident Response -> How do you anticipate, respond to, and recover from incidents?
- Automate incident/disaster recovery with cloudFormation
- Events can be automatically processed and trigger tool that automate responses
- Keep detailed logging
Reliability
The ability of a work-load to perform its intended function correctly and consistently when it’s expected to. The ability to operate and test the workload through its total lifecycle.
Design principe for Reliability
![]()
- Automatically recover from failure Monitor and Automate trigger when a limit/threshold is breached (KPI)
- Test recovery procedures
- Scale horizontally Replace one large resource into multiple small resource to reduce impact of single failure
- Stop guessing capacity Automate autoscaling and avoid resource saturation
- Manage Change in automation, not manually and keep track and review
Best practice for Reliability
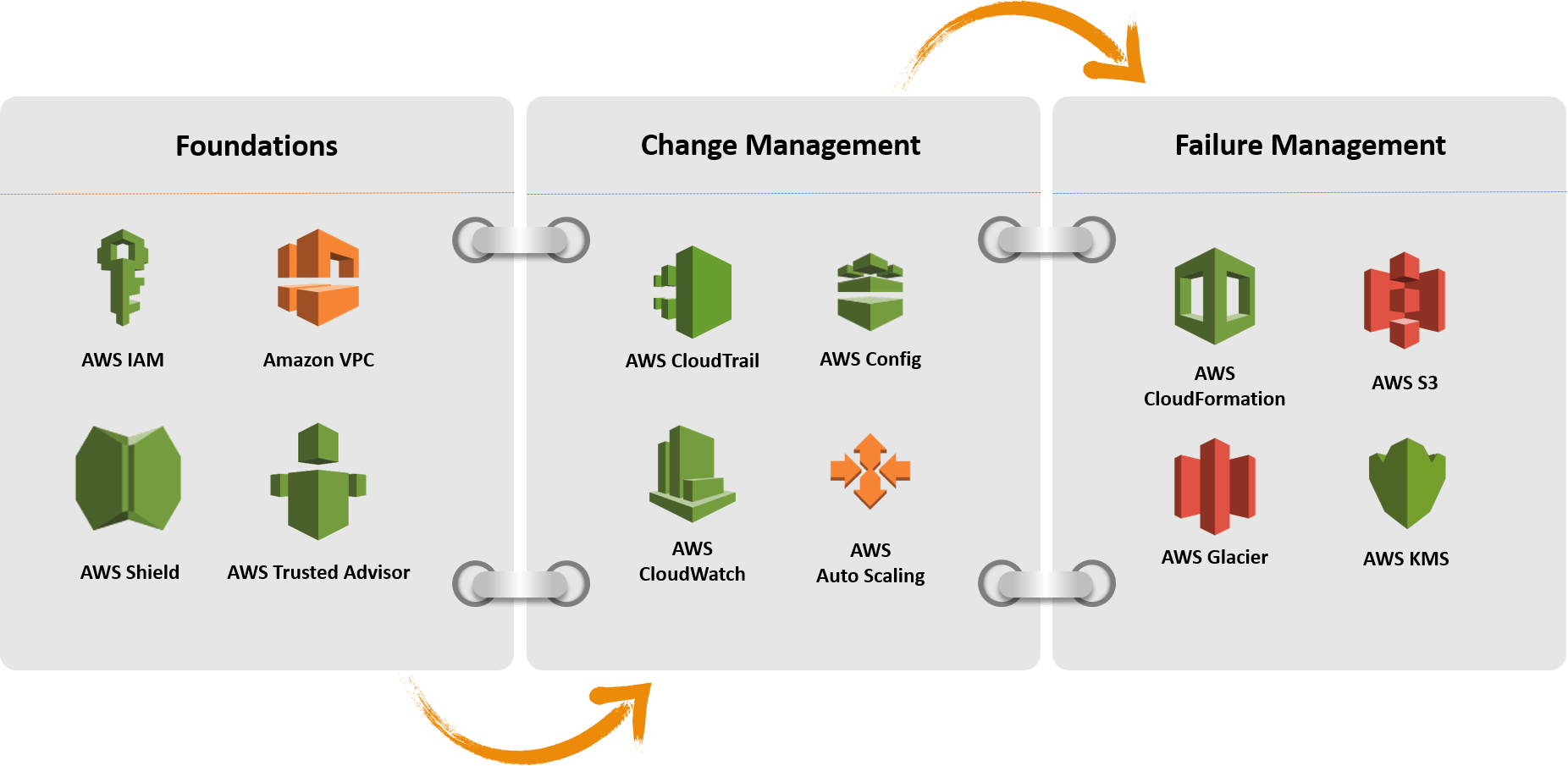
- Foundations of your infrastructure to avoid saturation
- How do you manage service quotas and constraint
- How do you plan your network topology
- Workload Architecture
- How do you design your workload service architecture?
- How do you design interactions in a distributed system to prevent failures?
- How do you design interactions in a distributed system to mitigate or withstandfailures?
- Change Management - Automate Change to trigger Action
- Changes to your workload or its environment must be anticipated and accommodated to achieve reliable operation of the workload. Changes like spikes in demand, new features deployment, security patches.
- How do you monitor workload resources?
- How do you design your workload to adapt to changes in demand?
- How do you implement change?
- Failure Management - Be aware of failure and react accordingly to avoid impact on availability
- Automate action based on monitoring
- How do you plan for disaster recovery (DR)?
- How do you use fault isolation to protect your workload?
- How do you design your workload to withstand component failures?
- How do you test reliability
- How do you back up data?
- Backup your data and test your backup files to be sure you can recover from both logical and physical errors
- Track KPI to identify and mitigate single point of failure
Performance efficiency
![]()
The ability to use computing resources efficiently to meet system requirements, and to maintain that efficiency as demand changes and technologies evolve.
Design principe for Performance efficiency
- Democratize advanced technologies -> New technologies as a service in the cloud like machine learning, transcoding, …
- Go Global in minutes
- Use ServerLess Architecture -> No need to maintain physical server
- Experiment more often - as it’s quick to deploy
- Consider mechanical sympathy Understand how cloud services are consumed and use the technology approach that align best with your workloads goals.
Best practice for Performance efficiency
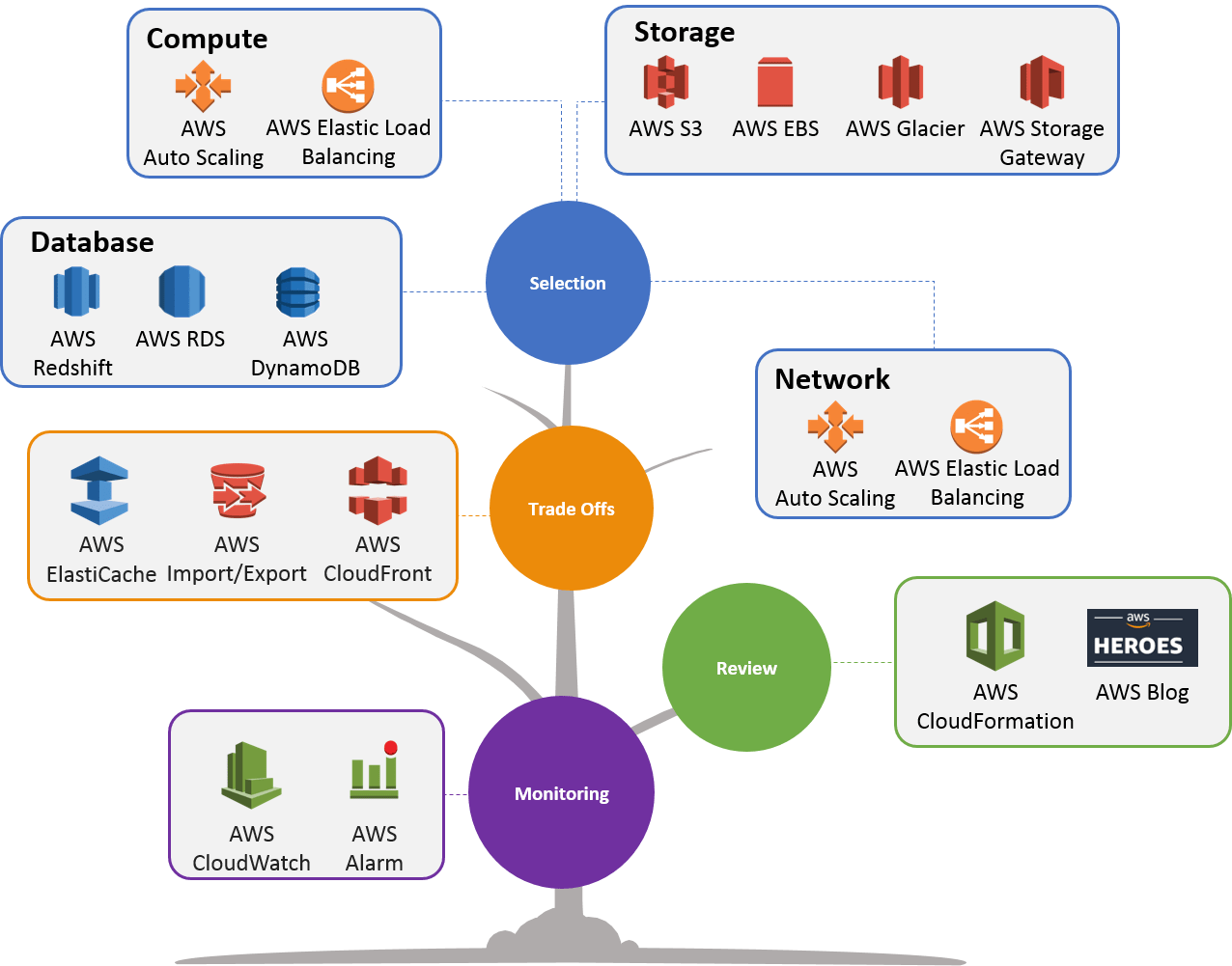
- Selection -> How do you select the best performing architecture?
- Select the resource follow your workload
- Compute -> How do you select your compute solution?
- Select the Compute follow your workload (Instances, container, function)
- Storage -> How do you select your storage solution?
- Object Storage S3
- Block Storage ( EBS )
- File Storage ( EFS qnd FSx )
- Database -> How do you select your database solution?
- Network -> How do you configure your networking solution?
- Compute -> How do you select your compute solution?
- Select the resource follow your workload
- Review -> How do you evolve your workload to take advantage of new releases?
- Review your system and take advantages of new technologies
- Monitoring -> How do you monitor your resources to ensure they are performing?
- Use CloudWatch, AWS X-Ray
- Tradeoffs -> How do you use tradeoffs to improve performance?
- When you architect solutions, think about tradeoffs to ensure an optimal approach. Depending on your situation, you could trade consistency, durability, and space for time or latency, to deliver higher performance.
The Cost Optimization pillar
![]()
The ability to run systems to deliver businessvalue at the lowest price point
Design principe for Cost Optimization
- Implement Cloud Financial Management
- Adopt a consumption model -> Pay only for the computing resources that you re-quire and increase or decrease usage depending on business requirements,
- Measure overall efficiency - balance between performance and cost
- Stop spending money on undifferentiated heavy lifting - no cost for datacenter and power, maintenance
- Analyze and attribute expenditure
Best practice for Cost Optimization
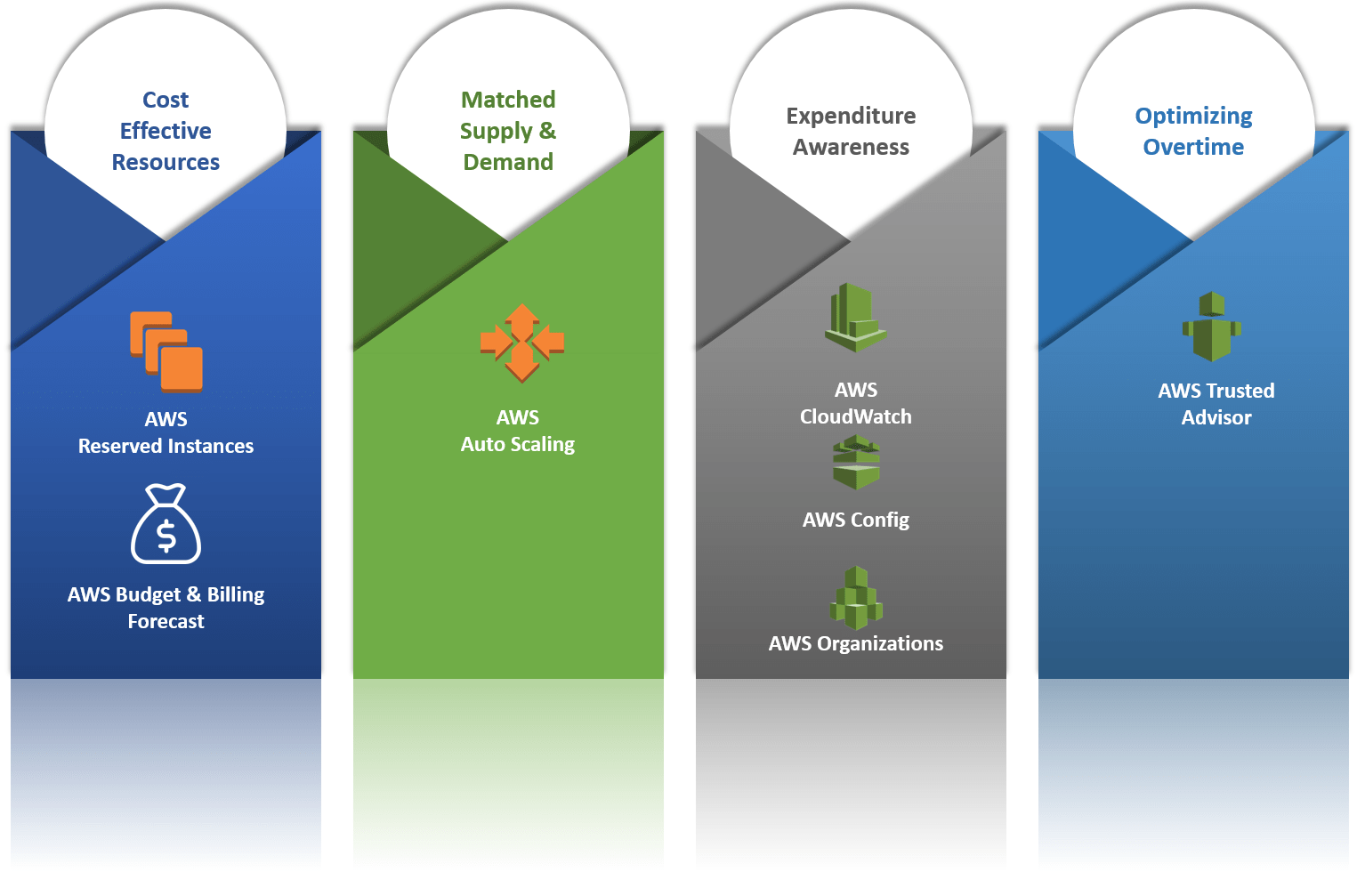
- Practice Cloud Financial Management How do you implement cloud financial management? -> Use AWS Cost Explorer, Budget and Amazon QuickSight with the Cost and Usage report. All company is using the same tools to have an overview of the cost by team and by system
- Expenditure and usage awareness How do you monitor usage and cost? How do you govern usage? How do you decommission resources?
- Cost-effective resources Using the appropriate instances and resources for your workload is key to cost saving
- How do you evaluate cost when you select services
- How do you meet cost targets when you select resource type, size and number?
- How do you use pricing models to reduce cost?
- How do you plan for data transfer charges
- Manage demand and supply resources - you pay on the cloud only for your need.
- How do you manage demand, and supply resources
- Optimize over time
- How do you evaluate new services?